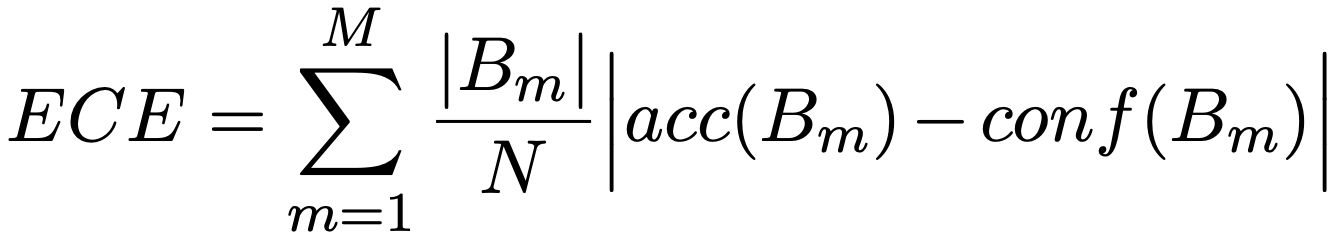本论文由腾讯 AI Lab 和清华大学合作完成,作者提出了一种评估神经机器翻译模型在推断场景下信心校准偏差的方法,并发现Transformer模型的信心尽管在训练场景中校准较好,但是在推断场景中仍然存在较大的校准偏差。以下为论文的详细解读。 On the Inference Calibration of Neural Machine Translation 基于概率的机器学习模型在给出预测结果的同时,往往会输出一个对应的信心指数(i.e., confidence),该信心指数可以代表模型对自身预测结果的正确性的一个估计。在金融、医疗等安全等级较高的场景中,我们希望模型不但有较好的预测精度(i.e., accuracy),并且能够做到“知之为知之,不知为不知”,对预测结果的正确性有准确的估计。 我们可以设想一个场景:在一个共同抗击疫情的各国联合医疗队中,各国医护人员可以使用机器翻译系统进行交流。在涉及患者病情的关键性描述中,我们要求机器翻译系统要如实反映其对翻译结果的信心。对于模型不自信的翻译结果,我们可以请语言专家有针对性的进行后处理,对于大部分模型自信的结果,我们可以直接使用。由此可见,对自身输出结果是否有一个准确的信心估计,是衡量机器翻译模型能否实际部署的重要性质。 量化模型对预测结果信心校准偏差的前人工作大多是在分类任务上开展的。但是,不同于分类任务的单一输出,包括机器翻译在内的生成式自然语言任务的输出都是序列化的,并且往往具有潜在的语义结构。如何评估序列化生成模型的信心校准偏差依然是一个尚未解决的问题。 在本文中,我们对期望校准偏差(Expected Calibration Error, ECE)进行了扩展,使其能够应用到序列化生成任务中来。具体地,ECE在计算方式如下:
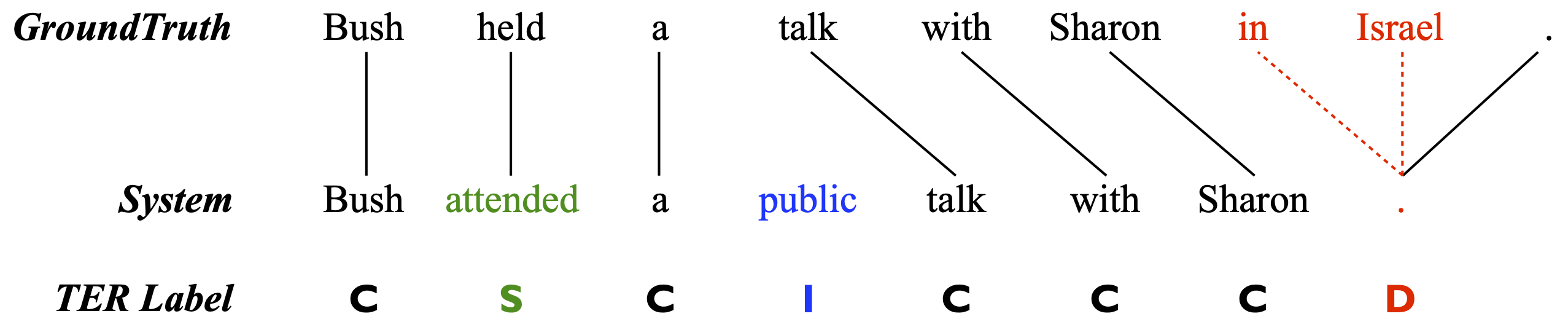
我们首先将模型在测试集中所有预测的token分为M组,分组的标准是每个token对应的信心指数(具体地,我们使用模型的翻译概率作为信心指数),信心指数相近的token会被分到同一组。在每一组中我们计算所有token的平均准确率和平均信心指数。对所有组的平均准确率与平均信心指数的偏差进行加权平均,将会得到最终的ECE结果。 为了计算ECE,一个关键是如何量化每个token的准确性。为此,我们使用TER方法在模型译文和参考译文之间建立一个对应关系,并根据TER的标注决定每个token的正确性:
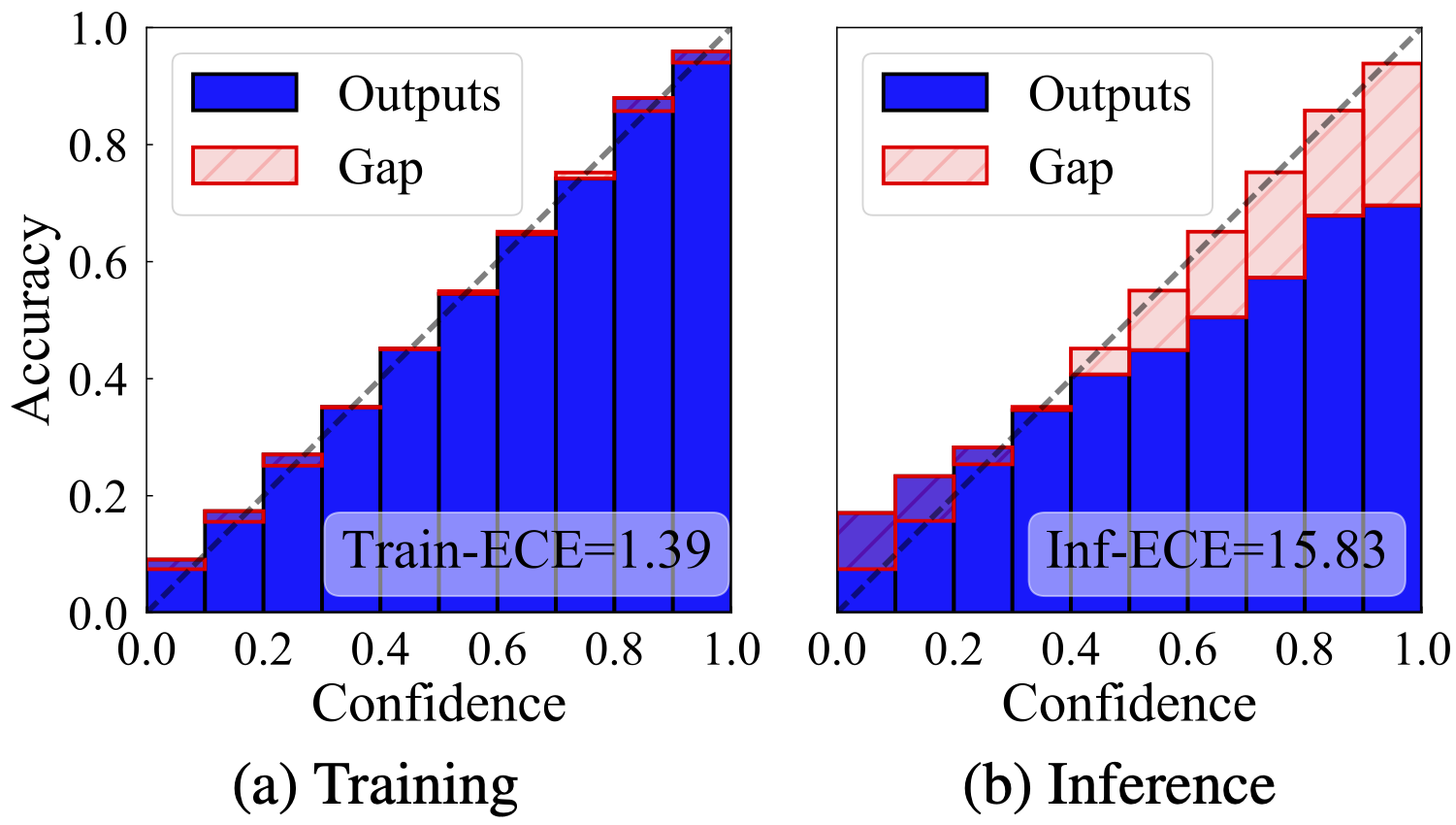
至此,我们就可以使用ECE量化序列化生成模型在推断场景下的信心校准偏差了。 在实验中,我们比较了机器翻译模型分别在训练与推断场景下信心校准偏差的情况:
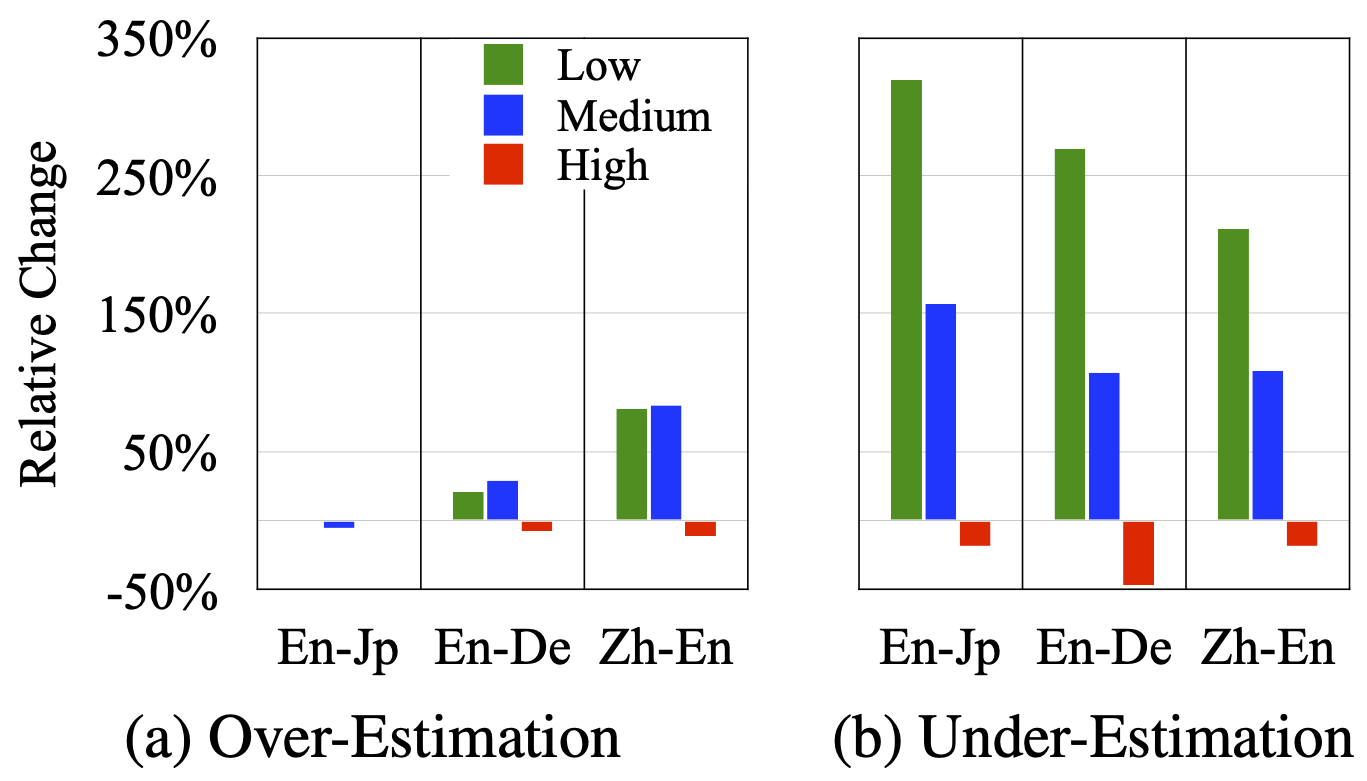
可以看到模型在推断阶段的ECE远远高于在训练阶段的ECE (15.83 > 1.39),说明推断阶段的信心校准偏差对目前的机器翻译模型来说仍然是一个问题。为了深入理解模型信心校准的特性,我们分析了信心失准的token的语言学性质。首先,我们比较了不同频率的token的特性:
实验发现模型在高频词上更不容易发生信心失准,而在中低频词上更容易发生信心失准。我们从相对位置、繁殖力、词性、词粒度等角度分析了模型的信心校准情况,详情请见论文。 为了探究当前深度学习技术与模型信心校准性质的影响,我们受 Guo et al., 2017 的启发,研究了正则化技术对机器翻译模型的影响:
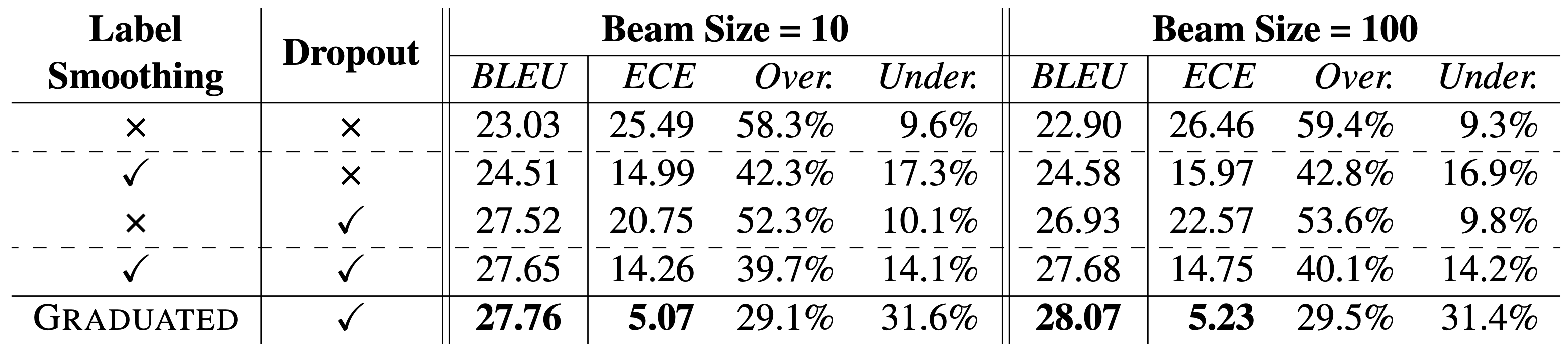
实验发现,dropout和label smoothing这两个在Transformer模型中非常常用的正则化技术有利于降低模型的ECE。基于实验发现,我们提出了一种Graduated label smoothing的方法,可以进一步减小模型在推断场景下的ECE。具体地,我们的设计思想是对训练集中模型本身预测概率较高的样例使用较大的smoothing系数,对于预测概率较低的样例使用较小的smoothing系数。 我们还分析了ECE与模型大小的关系:
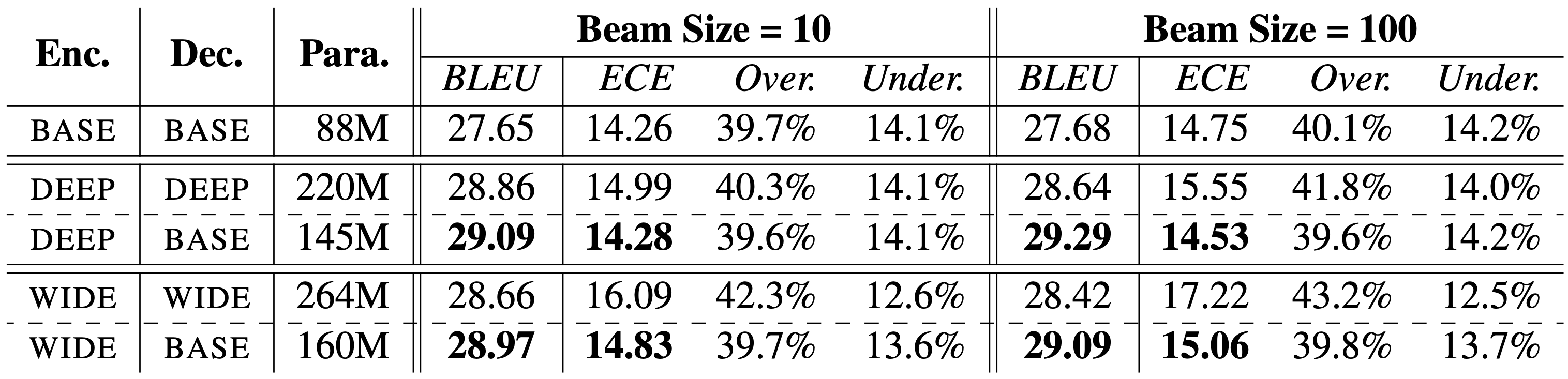
实验发现尽管增大模型会提高翻译的BLEU值,但是也会导致模型的ECE升高,这是增大模型参数量的一个弊端。另外我们发现这个问题可以通过只增大编码器,保持解码器不变这一简单策略在一定程度上缓解。 |