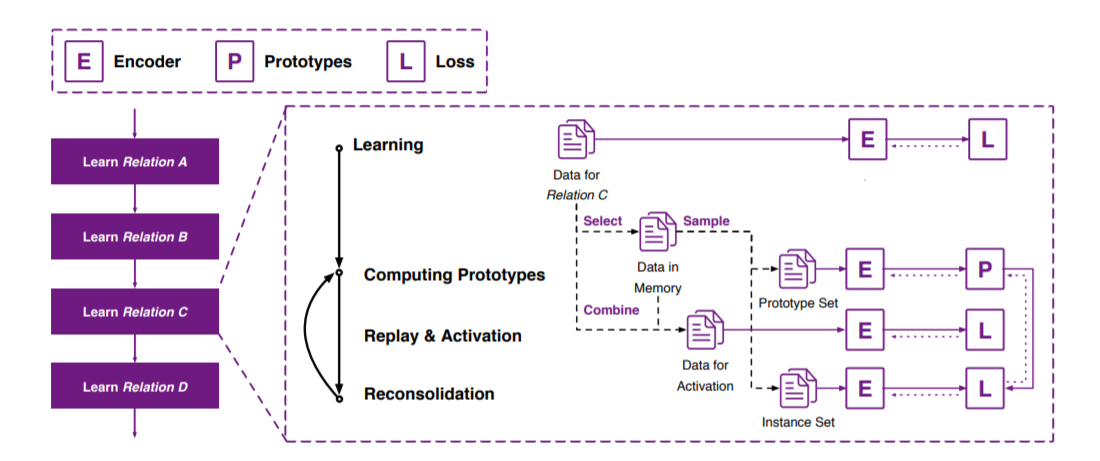
本文基于AAAI-2020论文《Continual Relation Learning via Episodic Memory Activation and Reconsolidation》,论文由清华大学和腾讯微信AI团队合作完成。 导语:在智能搜索、自动问答等现实应用中,知识图谱正在扮演越来越重要的作用,图谱中丰富的结构化信息可以辅助实现更加精细的语义理解。为了不断地完善现有知识图谱的覆盖度,关系抽取被广泛研究,力图从无结构化的海量文本中挖掘出结构化知识。然而,在现实的开放文本环境下,实体间新的语义关系也在不断出现,如何持续地学习这些新关系就成为了一大难题,尤其在不大量使用历史数据反复重新训练模型的前提下。对此,作者提出一套持续关系学习模型,支持模型不断地在新关系的数据上进行训练,在掌握新关系的特性的同时,避免灾难性地忘记旧关系的特性。具体而言,我们采用了基于情景记忆和记忆回放机制的持续学习框架,并额外引入了记忆再巩固阶段。再巩固阶段中,我们采用了原型学习的思路,确保每次情景记忆模块激活与回放后,旧关系的记忆样本与记忆原型依然匹配,使得模型能够较好地保留对旧关系的认知。作者在当前主流的关系学习数据集上进行了系统评测,与已有持续学习算法相比效果提升显著,模型记忆保持能力得到了充分验证。 模型背景与简介 信息抽取旨在从大规模非结构或半结构的自然语言文本中抽取结构化信息,关系抽取是其中的重要子任务之一,用以从文本中检测实体之间的丰富语义关系。例如,给定句子“牛顿担任英国皇家学会主席”,可以从中提取出牛顿与英国皇家学会之间的会员从属关系。通过关系抽取,我们可以极大地丰富知识图谱中的结构化信息,进而作为各类下游应用的外部资源。 传统的关系抽取方法主要侧重于识别预定义关系集中的关系。然而,这样的设定在实际工作场景下是非常受限的。在现实的开发文本场景下,新生的关系在源源不断地出现,作用于预定义关系集合的传统关系抽取方法无法解决这些新关系。为了在开放域下能够持续地处理新关系,最近的相关工作可以被归纳为两个方面:(1)开放关系抽取。学习提取句子中的词法、句法结构来构造特定的关系模式,通过聚类算法从中发现新的关系类型,并在大规模文本语料中扩展包含这些新关系语义的样本;(2)持续关系学习。不断使用新关系及其样本,来训练出一个高效的分类器。分类器将接受一系列任务的训练,每个任务都对应一个特定关系集合的,最终分类器能够同时处理现有和新出现关系的判别。虽然持续关系学习对于学习不断出现新关系至关重要,但相比于开放关系抽取,该领域仍然没有被充分探索。 对于持续关系学习,一种简单有效的方法是在每次出现新的关系及其对应样本时,都把它们存储进来一同参与训练,形成一种多任务学习的模式。然而,由于关系数量在持续增长,每个关系也拥有大量样本,频繁地混合新旧样本导致计算成本极为高昂。近期的一些工作提出了一些基于情景记忆和记忆重演的方法,即保存一些历史任务的训练样本,在未来重新训练,以维持分类器对历史数据的认知。这种记忆模型的主要问题在于易于过拟合少数的记忆样本,它们频繁改变旧关系的特征分布,逐渐过拟合记忆中的那些样本,在长期学习中逐渐发生混淆。因而提出一个能够在持续关系学习中较好地维持记忆、减少混淆,同时学习新出现关系的模型,就十分具有意义。 神经科学中有这样的发现,信息的重演、巩固有助于长期记忆的形成。已形成的长期记忆在被检索激活后,脑内的再巩固机制会对记忆进行再次存储。在再巩固阶段中,被激活的记忆十分脆弱,且易被更改。因而,在这个过程中,引入特殊的练习可以起到编辑记忆或强化记忆的作用。出于此,作者提出一种基于情景记忆激活与再巩固的持续关系学习算法(Episodic Memory Activation and Reconsolidation ,EMAR),在已有记忆与重演的基础上,引入了额外的记忆再巩固阶段。在每次神经网络被激活以学习新关系前,EMAR从历史关系的记忆样本中采样部分,用以计算历史关系的记忆原型。在神经网络被激活并完成一定的新关系学习后,EMAR会启动再巩固机制,确保历史关系的所有记忆样本能与相应记忆原型匹配,以此提升模型在学习新关系后对旧关系认知的保持能力。 模型结构
图1:EMAR的整体模型架构 图1给出了EMAR模型的整体架构。在开始一个新任务的学习时,模型通过编码器得出新关系样本的特征向量,给出涉及新关系的判断结果,并通过判断结果对编码器参数进行微调,从而最终学习新关系的特性。在一个新任务学习后,模型需要从这些已经学习的新关系样本中抽取一部分,以尽可能代表该任务中新关系在特征空间里的分布,保存在记忆中。这些记忆样本将在后续记忆重演、再巩固机制里发挥作用,对编码器与分类器进行进一步的参数优化,以确保既能够学习掌握新关系同时避免遗忘旧关系。 我们可以将持续关系抽取视作一系列任务上的训练,每个任务分为训练集 更具体地: (1)模型从样本中抽取句子语义信息、头尾实体位置等多种信息,解析成一个标记序列,再将标记输入神经网络,计算出相应的嵌入向量,用于进行实体关系预测。样本编码操作可以用如下方程表示: 这里, (2)当第k个任务出现时,模型还尚未了解该任务中的新关系,模型利用训练集 其中, (3)在若干次利用公式(2)进行迭代后,模型从 (4)在利用训练集 原型计算:通过结合所有情景记忆中的样本,模型获得了整体记忆集合 记忆重演和激活:将记忆集合
这里 记忆再巩固:正如前文背景部分介绍到,仅仅通过情景记忆的重演和激活会导致过拟合,在长期训练后,模型最终只能记住若干被记住的样本。同时,学习关系的核心在于掌握关系原型而非死记硬背关系样本。所以,每次进行记忆重演和激活后,作者添加了额外的再巩固阶段,并采取如下方式对记忆进行增强: 对于任一已知关系 其中 (5)整体训练过程如下图所示。
在第k个任务结束后,对于任一已知的关系
其中
其中pi是ri最终计算出的原型。最终,测试样本的预测值
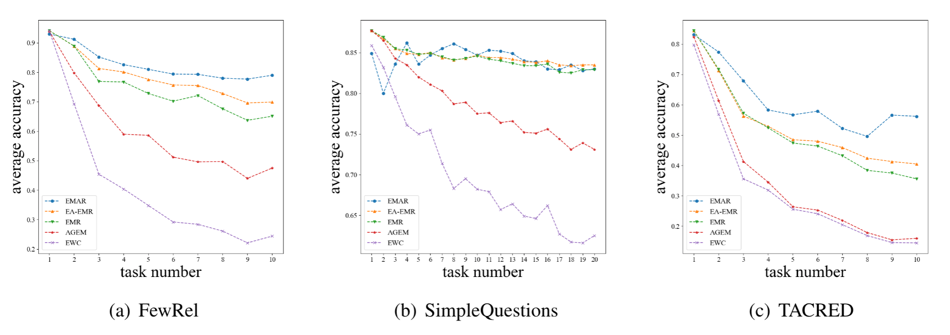
实验结果 作者在FewRel、SimpleQA、TACRED三个数据集上进行了测试。由于是持续关系学习,需要关注的是平均表现(Average)和整体表现(Whole),前者是模型在某个训练阶段时在所有已知关系数据上的平均结果,主要能够表现模型对记忆的保持能力,后者是模型对所有关系测试数据的结果。测试结果如下:
图2:持续学习表现测试结果 在两种指标下,EMAR模型除了SimpleQA的整体表现之外,在各个数据集上都得到了最佳的效果,说明了EMAR对于旧关系知识有较好的保持能力。图3也显示,随着任务的增长,EMAR预测结果的下降要更为缓慢,这也说明了EMAR更不容易遗忘历史知识。 实验通过Upper Bound指标说明SimpleQA数据集上已难产生显著提升。SimpleQA表现较为薄弱的另一个原因在于,SimpleQA的关系数量远大于记忆模块的容量, EMAR需要记忆模块对于每个关系至少保留一个样本,因而再巩固阶段与测试阶段,EMAR中关系的记忆原型无法运作,低记忆样本的启动问题将是我们下一步的研究点之一。
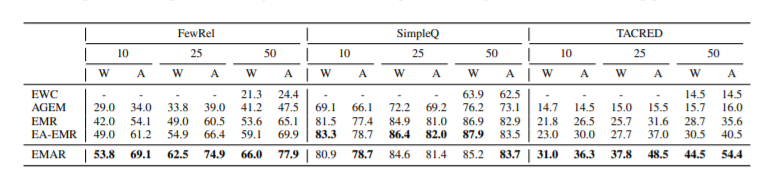
图3:任务增长下的预测结果变化 除此之外,作者还进行了多个记忆容量大小下的对比实验。以图4为例,可以发现随着记忆容量提高,各个模型的表现均有提升,说明记忆容量是决定持续关系学习模型表现的关键因素;对于FewRel和TACRED数据集,EMAR模型在各个记忆容量下都具有最好的表现,甚至和具有更大记忆容量的其他模型相比,说明EMAR模型中的记忆再巩固机制更有效得利用了记忆。
图4:不同记忆容量下的模型表现 总结 本文提出了一种新的持续关系学习方法EMAR,能够较好地维持对历史关系的认知,同时支持学习新出现的关系。通过在原有情景记忆与记忆重演模型基础上引入额外的记忆再巩固模块,并采用原型学习的思想确保历史关系在模型参数激活变更前后原型匹配,最终实现了学习新知识与记忆旧知识的优秀平衡。EMAR的有效性在现有的几个质量较高的数据集上也得到了验证。 |

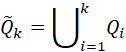
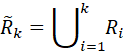
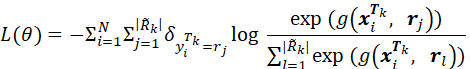

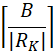
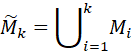
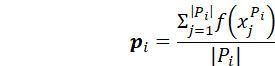
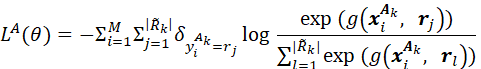
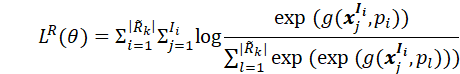

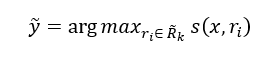 (8)
(8)