对服务进行实时监控,了解服务当前的运行指标和健康状态,是微服务体系中不可或缺的环节。Metrics 作为微服务的重要组件,为服务的监控提供了全面的数据基础。近日,Dubbo Metrics 发布了2.0.1版本,本文将为您探秘 Dubbo Metrics 的起源,及 7 大改进。
Dubbo Metrics 的起源Dubbo Metrics(原Alibaba Metrics)是阿里巴巴集团内部广泛使用的度量埋点基础类库,有 Java 和 Node.js 两个版本,目前开源的是 Java 版本。内部版本诞生于2016年,经历过近三年的发展和双十一的考验,已经成为阿里巴巴集团内部微服务监控度量的事实标准,覆盖了从系统、JVM、中间件到应用各层的度量,并且在命名规则、数据格式、埋点方式和计算规则等方面,形成了一套统一的规范。 Dubbo Metrics 的代码是基于 Dropwizard Metrics 衍生而来,版本号是3.1.0,当时决定 fork 到内部进行定制化开发的主要原因有两个。 一是社区的发展非常缓慢,3.1.0之后的第3年才更新了下一个版本,我们担心社区无法及时响应业务需求;另一个更重要的原因是当时的3.1.0还不支持多维度的 Tag,只能基于 a.b.c 这样传统的指标命名方法,这就意味着 Dropwizard Metrics 只能在单维度进行度量。然后,在实际的业务过程中,很多维度并不能事先确定,而且在大规模分布式系统下,数据统计好以后,需要按照各种业务维度进行聚合,例如按机房、分组进行聚合,当时的 Dropwizard 也无法满足,种种原因使得我们做了一个决定,内部fork一个分支进行发展。
Dubbo Metrics 做了哪些改进相对于 Dropwizard Metrics ,Dubbo Metrics 做的改进主要有以下几个方面:
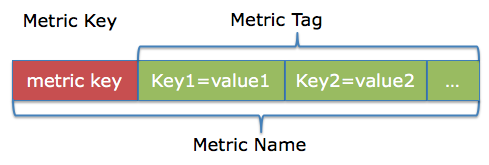
一、引入基于 Tag 的命名规范如前文所描述,多维度 Tag 在动态埋点,数据聚合等方面相对于传统的 metric 命名方法具有天然的优势,这里举一个例子,要统计一个
Dubbo 服务 DemoService 调用次数和 RT,假设这个服务叫做 DemoService,那么按照传统的命名方式,通常会命名为 通过引入Tag的概念,可以很好的解决了这个问题,我们将 metrics 分为两个部分,Key 和 Tag。
同时,考虑到一个公司所有微服务产生的所有指标,都会统一汇总到同一个平台进行处理,因此Metric Key 的命名方式为应当遵循同一套规范,避免发生命名冲突,其格式为
在上述例子中,同样的指标可以命名为
二、添加精准统计功能Dubbo Metrics 的精准统计是和 Dropwizard,或者其他开源项目埋点统计库实现不太一样的地方。下面分别通过时间窗口的选择和吞吐率统计方式这两个纬度进行阐述。 在统计吞吐率(如 QPS)的时候,Dropwizard的实现方式是滑动窗口+指数加权移动平均,也就是所谓的EWMA,在时间窗口上只提供1分钟、5分钟、15分钟的选择。 固定窗口 vs 滑动窗口 在数据统计的时候,我们需要事先定义好统计的时间窗口,通常有两种确立时间窗口的方法,分别是固定窗口和滑动窗口。 固定时间窗口指的是以绝对时间为参考坐标系,在一个绝对时间窗口内进行统计,无论何时访问统计数据,时间窗口不变;而滑动窗口则是以当前时间为参考系,从当前时间往前推一个指定的窗口大小进行统计,窗口随着时间,数据的变化而发生变化。 固定窗口的优点在于:一是窗口不需要移动,实现相对简单;二是由于不同的机器都是基于相同的时间窗口,集群聚合起来比较容易,只需按照相同的时间窗口聚合即可。其缺点是:如果窗口较大,实时性会受到影响,无法立即得到当前窗口的统计信息。例如,如果窗口为1分钟,则必须等到当前1分钟结束,才能得到这1分钟内的统计信息。 滑动窗口的优点在于实时性更好,在任意时刻,能都看到当前时刻往前推演一个时间窗口内统计好的信息。相对而言,由于不同机器的采集时刻不同,要把不同机器上的数据聚合到一起,则需要通过所谓的 Down-Sampling 来实现。即按照固定时间窗口把窗口内收集到的数据应用到某一个聚合函数上。举个例子来说,假设集群有5台机器,按照15秒的频率按照平均值进行 Down-Sampling,若在00:00~00:15的时间窗口内,在00:01,00:03,00:06,00:09,00:11各收集到一个指标数据,则把这5个点的加权平均认为是00:00这个点的经过 Down- Sampling 之后的平均值。 但在我们的实践过程中,滑动窗口仍会遇到了以下问题:
为了解决这些问题,Dubbo Metrics 提供了 BucketCounter 度量器,可以精确统计整分整秒的数据,时间窗口可以精确到1秒。只要每台机器上的时间是同步的,那么就能保证集群聚合后的结果是准确的。同时也支持基于滑动窗口的统计。
瞬时速率(Rate) vs 指数移动加权平均(EWMA) 经过多年的实践,我们逐渐发现,用户在观察监控的时候,首先关注的其实是集群数据,然后才是单机数据。然而单机上的吞吐率其实并没有太大意义。怎么理解呢? 比如有一个微服务,共有2台机器,某个方法在某一段时间内产生了5次调用,所花的时间分别是机器1上的[5,17],机器2上的[6,8,8](假设单位为毫秒)。如果要统计集群范围内的平均 RT,一种方法可以先统计单机上的平均 RT,然后统计整体的平均 RT,按照这种方法,机器1上平均 RT 为11ms,机器2的平均 RT 为7.33ms,两者再次平均后,得到集群平均 RT 为9.17ms,但实际的结果是这样吗? 如果我们把机器1和机器2上的数据整体拉到一起整体计算的话,会发现实际的平均
RT 为(5+17+6+8+8)/5=8.8ms,两者相差很明显。而且考虑到计算浮点数的精度丢失,以及集群规模扩大,这一误差会愈加明显。因此,我们得出一个结论:单机上的吞吐率对于集群吞吐率的计算没有意义,仅在在单机维度上看才是有意义的。
三、极致性能优化在大促场景下,如何提升统计性能,对于 Dubbo Metrics 来说是一个重要话题。在阿里的业务场景下,某个统计接口的 QPS 可能达到数万,例如访问 Cache 的场景,因此这种情况下 metrics 的统计逻辑很可能成为热点,我们做了一些针对性的优化: 高并发场景下,数据累加表现最好的就是
避免调用 LongAdder#reset 当数据过期之后,需要对数据进行清理,之前的实现里面为了重用对象,使用了
去除冗余累加操作 某些度量器的实现里面,有些统计维度比较多,需要同时更新多个 LongAdder,例如 DropwizardMetrics的 meter 实现里面计算1分/5分/15分移动平均,每次需要更新3个 LongAdder,但实际上这3次更新操作是重复的,只需要更新一次就行了。
RT为0时避免调用Add方法 大多数场景下对 RT 的统计都以毫秒为单位,有些时候当 RT 计算出来小于1ms的时候,传给metrics的 RT 为0。当我们发现 JDK 原生的 LongAdder 并没有对
QPS 和 RT 合并统计 只需要对一个Long的更新,即可实现同时对调用次数和时间进行统计,已经逼近理论上的极限。 经过观测发现,通常对于中间件的某些指标,成功率都非常高,正常情况下都在100%。为了统计成功率,需要统计成功次数和总次数,这种情况下几乎一样多,这样造成了一定的浪费,白白多做了一次加法。而如果反过来,只统计失败的次数,只有当失败的情况才会更新计数器,这样能大大降低加法操作。 事实上,如果我们把每一种情况进行正交拆分,例如成功和失败,这样的话,总数可以通过各种情况的求和来实现。这样能进一步确保一次调用只更新一次计数。 但别忘了,除了调用次数,还有方法执行 RT 要统计。还能再降低吗? 答疑是可以的!假设 RT 以毫秒为单位进行统计,我们知道1个 Long 有64个bits(实际上Java里面的Long是有符号的,所以理论上只有63个 bits 可用),而 metrics 的一个统计周期最多只统计60s的数据,这64个 bits 无论怎样用都是用不掉的。那能不能把这63个 bits 拆开来,同时统计 count 和 RT 呢?实际上是可以的。 我们把一个 Long 的63个 bits 的高25位用来表示一个统计周期内的总 count,低38位用于表示总RT。 当一次调用过来来的时候,假设传过来的 RT 是n,那么每次累加的数不是1,也不是n,而是
这么设计主要有一下几个考虑:
无锁 BucketCounter 在之前的代码中,BucketCounter 需要确保在多线程并发访问下保证只有一个线程对 Bucket 进行更新,因此使用了一个对象锁,在最新版本中,对 BucketCounter 进行了重新实现,去掉了原来实现中的锁,仅通过 AtomicReference 和 CAS 进行操作,本地测试发现性能又提升了15%左右。
四、全面的指标统计Dubbo Metrics 全面支持了从操作系统,JVM,中间件,再到应用层面的各级指标,并且对统一了各种命名指标,可以做到开箱即用,并支持通过配置随时开启和关闭某类指标的收集。目前支持的指标,主要包括:
支持Linux/Windows/Mac,包含CPU/Load/Disk/Net Traffic/TCP。
支持classload, GC次数和时间, 文件句柄,young/old区占用,线程状态, 堆外内存,编译时间,部分指标支持自动差值计算。
后续会陆续添加对Dubbo/Nacos/Sentinel/Fescar等的支持。
五、REST支持Dubbo Metrics 提供了基于 JAX-RS 的 REST 接口暴露,可以轻松查询内部的各种指标,既可以独立启动HTTP Server提供服务(默认提供了一个基于Jersey+ sun Http server的简单实现),也可以嵌入已有的HTTP Server进行暴露指标。具体的接口可以参考这里: https://github.com/dubbo/metrics/wiki/query-from-http
六、单机数据落盘数据如果完全存在内存里面,可能会出现因为拉取失败,或者应用本身抖动,导致数据丢失的可能。为了解决该问题,metrics引入了数据落盘的模块,提供了日志方式和二进制方式两种方式的落盘。
七、易用性和稳定性优化
如何使用使用方式很简单,和日志框架的Logger获取方式一致。
支持的度量器包括:
后续规划
参考资料Dubbo Metrics @Github: https://github.com/dubbo/metrics Wiki: https://github.com/dubbo/metrics/wiki (持续更新) |