在前面的文章中,我们分别介绍了 Ignite 和 Spark 这两种技术,从功能上对两者进行了全面深入的对比。经过分析,可以得出这样一个结论:两者都很强大,但是差别很大,定位不同,因此会有不同的适用领域。 但是,这两种技术也是可以互补的,那么它们互补适用于场景是什么呢?主要是这么几个方面:如果觉得 Spark 中的 SQL 等运行速度较慢,那么 Ignite 通过自己的方式提供了对 Spark 应用进行进一步加速的解决方案,这方面可选的解决方案并不多,推荐开发者考虑,另外就是数据和状态的共享,当然这方面的解决方案也有很多,并不是一定要用 Ignite 实现。 Ignite 原生提供了对 Spark 的支持,本文主要探讨为何与如何将 Ignite 和 Spark 进行集成。 1.将 Ignite 与 Spark 整合整合这两种技术会为 Spark 应用带来若干明显的好处:
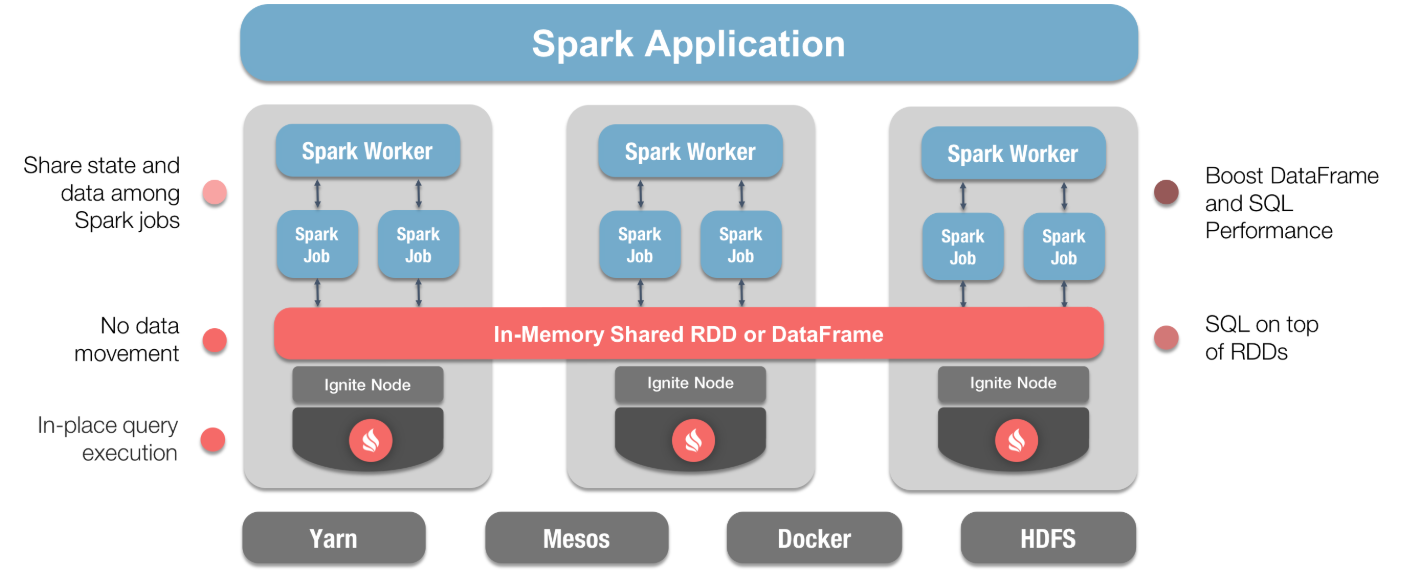
下图显示了如何整合这两种技术,并且标注了显著的优势:
通过该图,可以从整体架构的角度看到 Ignite 在整个 Spark 应用中的位置和作用。 Ignite 对 Spark 的支持主要体现为两个方面,一个是 Ignite RDD,一个是 Ignite DataFrame。本文会首先聚焦于 Ignite RDD,之后再讲讲 Ignite DataFrame。 2.Ignite RDDIgnite 提供了一个
Ignite 还可以帮助 Spark 应用提高 SQL 的性能,虽然 SparkSQL 支持丰富的 SQL 语法,但是它没有实现索引。从结果上来说,即使在普通较小的数据集上,Spark 查询也可能花费几分钟的时间,因为需要进行全表扫描。如果使用 Ignite,Spark 用户可以配置主索引和二级索引,这样可以带来上千倍的性能提升。 2.1.IgniteRDD 示例下面通过一些代码以及创建若干应用的方式,展示 IgniteRDD 带来的好处。 可以使用多种语言来访问 Ignite RDD,这对于有跨语言需求的团队来说有友好的,下边代码共包括两个简单的 Scala 应用和两个 Java 应用。此外,会从两个不同的环境运行应用:从终端运行 Scala 应用以及通过 IDE 运行 Java 应用。另外还会在 Java 应用中运行一些 SQL 查询。 对于 Scala 应用,一个应用会用于往 IgniteRDD 中写入数据,而另一个应用会执行部分过滤然后返回结果集。使用 Maven 将代码构建为一个 jar 文件后在终端窗口中执行这个程序,下面是详细的代码: object RDDWriter extends App {
val conf = new SparkConf().setAppName("RDDWriter")
val sc = new SparkContext(conf)
val ic = new IgniteContext(sc, "/path_to_ignite_home/examples/config/spark/example-shared-rdd.xml")
val sharedRDD: IgniteRDD[Int, Int] = ic.fromCache("sharedRDD")
sharedRDD.savePairs(sc.parallelize(1 to 1000, 10).map(i => (i, i)))
ic.close(true)
sc.stop()
}
object RDDReader extends App {
val conf = new SparkConf().setAppName("RDDReader")
val sc = new SparkContext(conf)
val ic = new IgniteContext(sc, "/path_to_ignite_home/examples/config/spark/example-shared-rdd.xml")
val sharedRDD: IgniteRDD[Int, Int] = ic.fromCache("sharedRDD")
val greaterThanFiveHundred = sharedRDD.filter(_._2 > 500)
println("The count is " + greaterThanFiveHundred.count())
ic.close(true)
sc.stop()
}
在这个 Scala 的 在这个 Scala 的 关于 要构建 jar 文件,可以使用下面的 maven 命令: mvn clean install 接下来,看下 Java 代码,先写一个 Java 应用往 public class RDDWriter {
public static void main(String args[]) {
SparkConf sparkConf = new SparkConf().setAppName("RDDWriter").setMaster("local").set("spark.executor.instances", "2");
JavaSparkContext sparkContext = new JavaSparkContext(sparkConf);
Logger.getRootLogger().setLevel(Level.OFF);
Logger.getLogger("org.apache.ignite").setLevel(Level.OFF);
JavaIgniteContext<Integer, Integer> igniteContext = new JavaIgniteContext<Integer, Integer>(
sparkContext, "/path_to_ignite_home/examples/config/spark/example-shared-rdd.xml", true);
JavaIgniteRDD<Integer, Integer> sharedRDD = igniteContext.<Integer, Integer>fromCache("sharedRDD");
List<Integer> data = new ArrayList<>(20);
for (int i = 1001; i <= 1020; i++) {
data.add(i);
}
JavaRDD<Integer> javaRDD = sparkContext.<Integer>parallelize(data);
sharedRDD.savePairs(javaRDD.<Integer, Integer>mapToPair(new PairFunction<Integer, Integer, Integer>() {
public Tuple2<Integer, Integer> call(Integer val) throws Exception {
return new Tuple2<Integer, Integer>(val, val);
}
}));
igniteContext.close(true);
sparkContext.close();
}
}
在这个 Java 的 在这个 Java 的 public class RDDReader {
public static void main(String args[]) {
SparkConf sparkConf = new SparkConf().setAppName("RDDReader").setMaster("local").set("spark.executor.instances", "2");
JavaSparkContext sparkContext = new JavaSparkContext(sparkConf);
Logger.getRootLogger().setLevel(Level.OFF);
Logger.getLogger("org.apache.ignite").setLevel(Level.OFF);
JavaIgniteContext<Integer, Integer> igniteContext = new JavaIgniteContext<Integer, Integer>(
sparkContext, "/path_to_ignite_home/examples/config/spark/example-shared-rdd.xml", true);
JavaIgniteRDD<Integer, Integer> sharedRDD = igniteContext.<Integer, Integer>fromCache("sharedRDD");
JavaPairRDD<Integer, Integer> greaterThanFiveHundred = sharedRDD.filter(new Function<Tuple2<Integer, Integer>, Boolean>() {
public Boolean call(Tuple2<Integer, Integer> tuple) throws Exception {
return tuple._2() > 500;
}
});
System.out.println("The count is " + greaterThanFiveHundred.count());
System.out.println(">>> Executing SQL query over Ignite Shared RDD...");
Dataset df = sharedRDD.sql("select _val from Integer where _val > 10 and _val < 100 limit 10");
df.show();
igniteContext.close(true);
sparkContext.close();
}
}
到这里就可以对代码进行测试了。 2.2.运行应用在第一个终端窗口中,启动 Spark 的主节点,如下: $SPARK_HOME/sbin/start-master.sh 在第二个终端窗口中,启动 Spark 工作节点,如下: $SPARK_HOME/bin/spark-class org.apache.spark.deploy.worker.Worker spark://ip:port 根据自己的环境,修改 IP 地址和端口号(ip:port)。 在第三个终端窗口中,启动一个 Ignite 节点,如下: $IGNITE_HOME/bin/ignite.sh examples/config/spark/example-shared-rdd.xml 这里使用了之前讨论过的 在第四个终端窗口中,可以运行 Scala 版的 RDDWriter 应用,如下: $SPARK_HOME/bin/spark-submit --class "com.gridgain.RDDWriter" --master spark://ip:port "/path_to_jar_file/ignite-spark-scala-1.0.jar" 根据自己的环境修改 IP 地址和端口(ip:port),以及 jar 文件的路径(/path_to_jar_file)。 会产生如下的输出: The count is 500 这是期望的输出。 接下来,杀掉 Spark 的主节点和工作节点,而 Ignite 节点仍然在运行中并且 运行 Java 版 The count is 520 这也是期望的输出。 最后,SQL 查询会在
结果正确。 3.IgniteDataframesSpark 的 DataFrame API 为描述数据引入了模式的概念,Spark 通过表格的形式进行模式的管理和数据的组织。 DataFrame 是一个组织为命名列形式的分布式数据集,从概念上讲,DataFrame 等同于关系数据库中的表,并允许 Spark 使用 Catalyst 查询优化器来生成高效的查询执行计划。而 RDD 只是跨集群节点分区化的元素集合。 Ignite 扩展了 DataFrames,简化了开发,改进了将 Ignite 作为 Spark 的内存存储时的数据访问时间,好处包括:
3.1.IgniteDataframes 示例下面通过一些代码以及搭建几个小程序的方式,了解如何通过 Ignite DataFrames 整合 Ignite 与 Spark。 一共会写两个 Java 的小应用,然后在 IDE 中运行,还会在这些 Java 应用中执行一些 SQL 查询。 一个 Java 应用会从 JSON 文件中读取一些数据,然后创建一个存储于 Ignite 的 DataFrame,这个 JSON 文件 Ignite 的发行版中已经提供,另一个 Java 应用会从 Ignite 的 DataFrame 中读取数据然后使用 SQL 进行查询。 下面是写应用的代码: public class DFWriter {
private static final String CONFIG = "config/example-ignite.xml";
public static void main(String args[]) {
Ignite ignite = Ignition.start(CONFIG);
SparkSession spark = SparkSession.builder().appName("DFWriter").master("local").config("spark.executor.instances", "2").getOrCreate();
Logger.getRootLogger().setLevel(Level.OFF);
Logger.getLogger("org.apache.ignite").setLevel(Level.OFF);
Dataset<Row> peopleDF = spark.read().json(
resolveIgnitePath("resources/people.json").getAbsolutePath());
System.out.println("JSON file contents:");
peopleDF.show();
System.out.println("Writing DataFrame to Ignite.");
peopleDF.write().format(IgniteDataFrameSettings.FORMAT_IGNITE()).option(IgniteDataFrameSettings.OPTION_CONFIG_FILE(), CONFIG).option(IgniteDataFrameSettings.OPTION_TABLE(), "people").option(IgniteDataFrameSettings.OPTION_CREATE_TABLE_PRIMARY_KEY_FIELDS(), "id").option(IgniteDataFrameSettings.OPTION_CREATE_TABLE_PARAMETERS(), "template=replicated").save();
System.out.println("Done!");
Ignition.stop(false);
}
}
在 public class DFReader {
private static final String CONFIG = "config/example-ignite.xml";
public static void main(String args[]) {
Ignite ignite = Ignition.start(CONFIG);
SparkSession spark = SparkSession.builder().appName("DFReader").master("local").config("spark.executor.instances", "2").getOrCreate();
Logger.getRootLogger().setLevel(Level.OFF);
Logger.getLogger("org.apache.ignite").setLevel(Level.OFF);
System.out.println("Reading data from Ignite table.");
Dataset<Row> peopleDF = spark.read().format(IgniteDataFrameSettings.FORMAT_IGNITE()).option(IgniteDataFrameSettings.OPTION_CONFIG_FILE(), CONFIG).option(IgniteDataFrameSettings.OPTION_TABLE(), "people").load();
peopleDF.createOrReplaceTempView("people");
Dataset<Row> sqlDF = spark.sql("SELECT * FROM people WHERE id > 0 AND id < 6");
sqlDF.show();
System.out.println("Done!");
Ignition.stop(false);
}
}
在 在 IDE 中,通过下面的代码可以启动一个 Ignite 节点: public class ExampleNodeStartup {
public static void main(String[] args) throws IgniteException {
Ignition.start("config/example-ignite.xml");
}
}
到此,就可以对代码进行测试了。 3.2.运行应用首先在 IDE 中启动一个 Ignite 节点,然后运行
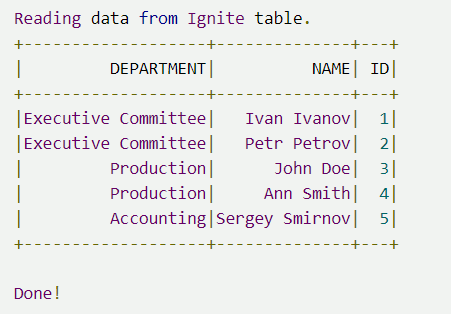
如果将上面的结果与 JSON 文件的内容进行对比,会显示两者是一致的,这也是期望的结果。 下一步运行
这也是期望的输出。 4.总结通过本文,会发现 Ignite 与 Spark 的集成很简单,也可以看到如何从多个环境中使用多个编程语言轻松地访问 如果想要这些示例的源代码,可以从这里下载。 作者李玉珏,架构师,有丰富的架构设计和技术研发团队管理经验,社区技术翻译作者以及撰稿人,开源技术贡献者。Apache Ignite 技术中文文档翻译作者,长期在国内进行 Ignite 技术的推广/技术支持/咨询工作。 |