今年 5 月的人机对局中,柯洁 9 段以 0:3 不敌 AlphaGo,随后 Deepmind 在围棋上进一步探索。Nature 今天的论文就详细介绍了谷歌 DeepMind 团队最新的研究成果。
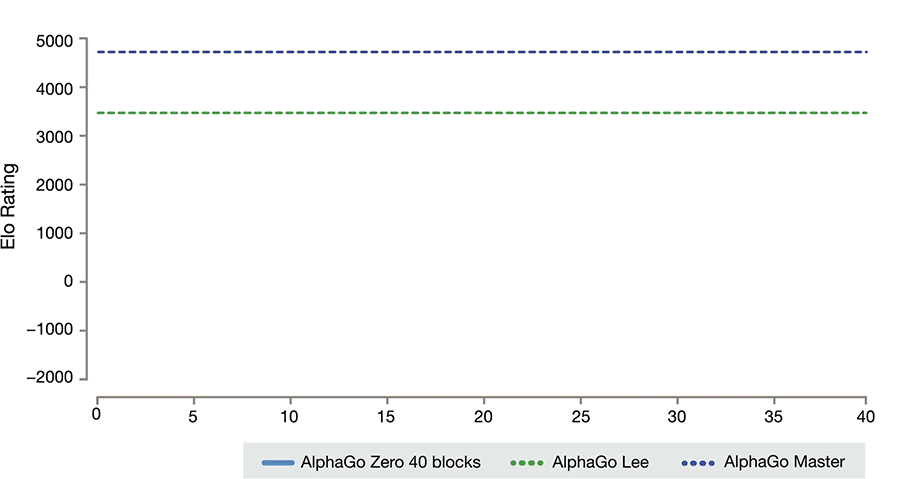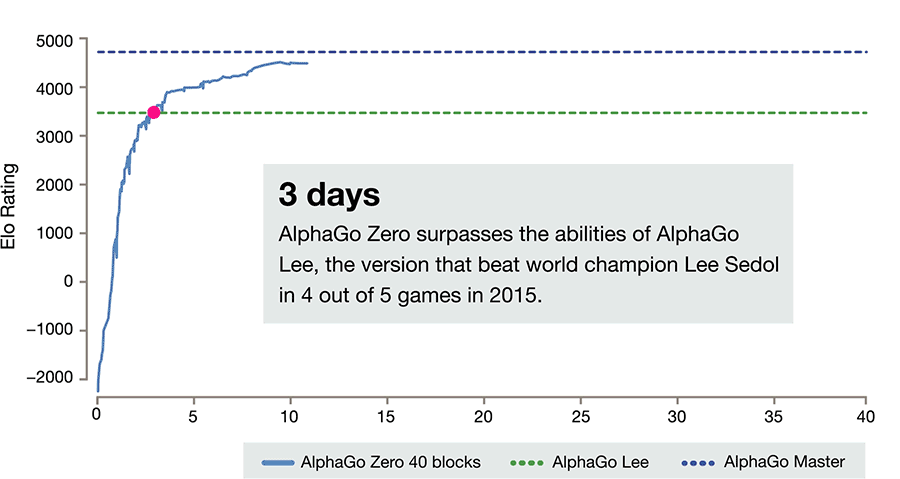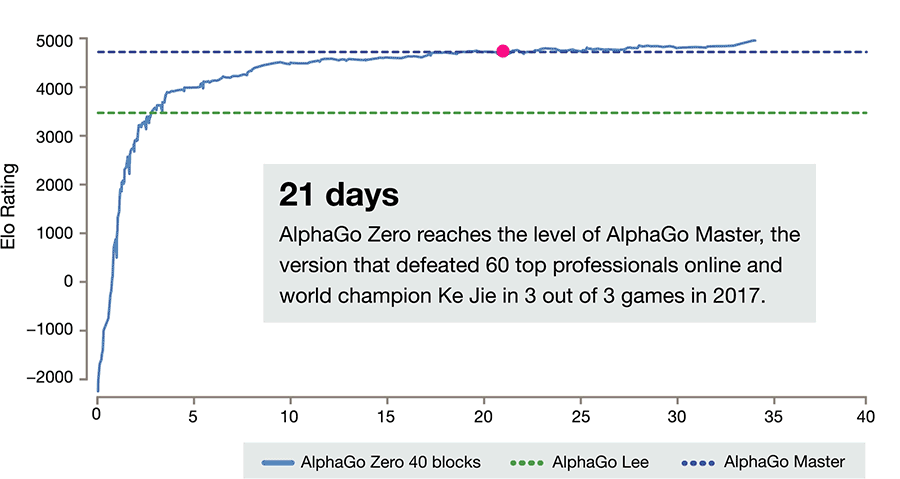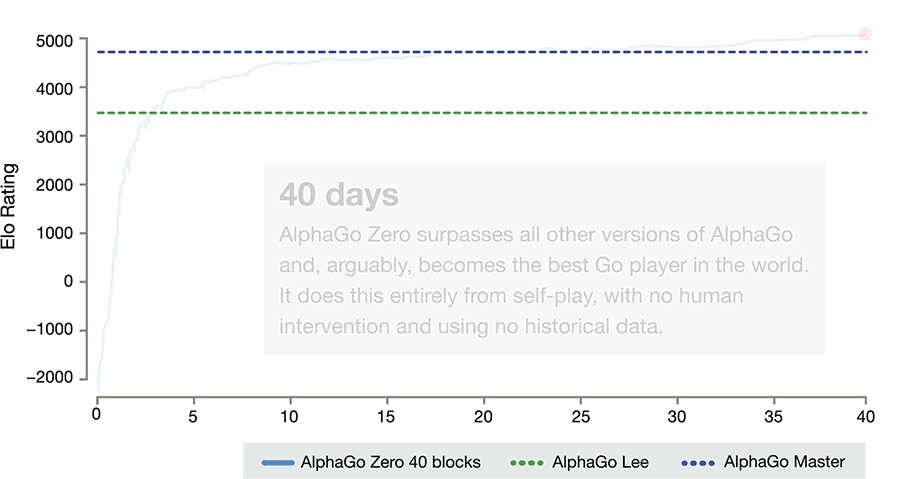
阿法狗战胜人类,其棋艺的精进是建立在计算机对海量历史棋谱学习参悟的基础之上,实现自我进化和超越。 而新一代的阿法元(AlphaGo Zero)完全是从零开始,不需要任何历史和人类的指导,通过全新的强化学习方式自己成为自己的老师,在棋艺上不仅达到了超越人类的精通程度,也打败了它的师兄阿法狗(AlphaGo)。
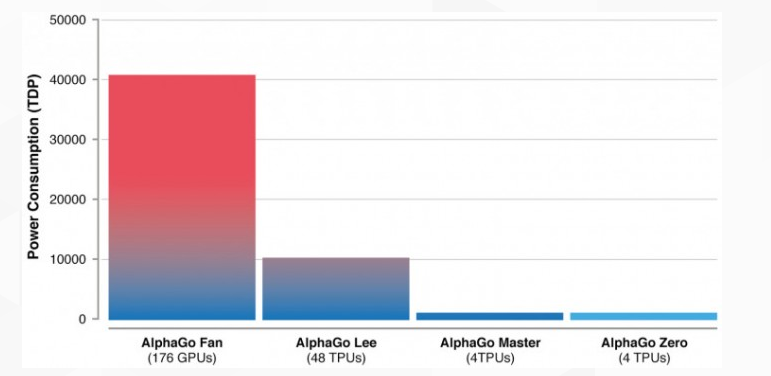
达到这样一个水准,阿法元只需要在4个TPU上,花三天时间,自己左右互搏490万棋局。而它的师兄阿法狗,需要在48个TPU上,花几个月的时间,学习三千万棋局,才打败人类。
美国杜克大学人工智能专家陈怡然教授在接受知社采访了时,说到:这恰好证明了人类经验由于样本空间大小的限制,往往都收敛于局部最优而不自知(或无法发现),而机器学习可以突破这个限制。之前大家隐隐约约觉得应该如此,而现在是铁的量化事实摆在面前! 虽然这一技术还处于早期阶段,但阿法元(AlphaGo Zero)的突破使得我们在未来面对人类面对的一些重大挑战时充满信心(如能源问题)。 人工智能到底将何去何从?如果将该技术应用到其他问题上,会对我们的生活产生哪些根本性的影响呢? |