当你需要保存日期时间数据时,一个问题来了:你应该使用 MySQL 中的什么类型?使用 MySQL 原生的 DATE 类型还是使用 INT 字段把日期和时间保存为一个纯数字呢? 在这篇文章中,我将解释 MySQL 原生的方案,并给出一个最常用数据类型的对比表。我们也将对一些典型的查询做基准测试,然后得出在给定场景下应该使用什么数据类型的结论。 如果你想直接看结论,请翻到文章最下方。 原生的 MySQL Datetime 数据类型Datetime 数据表示一个时间点。这可以用作日志记录、物联网时间戳、日历事件数据,等等。MySQL 有两种原生的类型可以将这种信息保存在单个字段中:Datetime 和 Timestamp。MySQL 文档中是这么介绍这些数据类型的: DATETIME 类型用于保存同时包含日期和时间两部分的值。MySQL 以 ‘YYYY-MM-DD HH:MM:SS’ 形式接收和显示 DATETIME 类型的值。 TIMESTAMP 类型用于保存同时包含日期和时间两部分的值。 DATETIME 或 TIMESTAMP 类型的值可以在尾部包含一个毫秒部分,精确度最高到微秒(6 位数)。 TIMESTAMP 和 DATETIME 数据类型提供自动初始化和更新到当前的日期和时间的功能,只需在列的定义中设置 DEFAULT CURRENTTIMESTAMP 和 ON UPDATE CURRENTTIMESTAMP。
作为一个例子:
|
CREATE TABLE `datetime_example` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`measured_on` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`id`),
KEY `measured_on` (`measured_on`)
) ENGINE=InnoDB;
|
|
CREATE TABLE `timestamp_example` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`measured_on` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`id`),
KEY `measured_on` (`measured_on`)
) ENGINE=InnoDB;
|
除了原生的日期时间表示方法,还有另一种常用的存储日期和时间信息的方法。即使用 INT 字段保存 Unix 时间(从1970 年 1 月 1 日协调世界时(UTC)建立所经过的秒数)。 MySQL 也提供了只保存时间信息中的一部分的方式,通过使用 Date、Year 或 Time 类型。由于这篇文章是关于保存准确时间点的最佳方式的,我们没有讨论这些不那么精确的局部类型。 使用 INT 类型保存 Unix 时间使用一个简单的 INT 列保存 Unix 时间是最普通的方法。使用 INT,你可以确保你要保存的数字可以快速、可靠地插入到表中,就像这样:
|
INSERT INTO `vertabelo`.`sampletable`
(
`id`,
`measured_on` ### INT 类型的列
)
VALUES
(
1,
946684801
### 至 01/01/2000 @ 12:00am (UTC) 的 UNIX 时间戳 http://unixtimestamp.com
);
|
这就是关于它的所有内容了。它仅仅是个简单的 INT 列,MySQL 的处理方式是这样的:在内部使用 4 个字节保存那些数据。所以如果你在这个列上使用 SELECT 你将会得到一个数字。如果你想把这个列用作日期进行比较,下面的查询并不能正确工作:
|
SELECT
id, measured_on, FROM_UNIXTIME(measured_on)
FROM
vertabelo.inttimestampmeasures
WHERE
measured_on > '2016-01-01' ### measured_on 会被作为字符串比较以进行查询
LIMIT 5;
|
这是因为 MySQL 把 INT 视为数字,而非日期。为了进行日期比较,你必须要么获取( LCTT 译注:从 1970-01-01 00:00:00)到 2016-01-01 经过的秒数,要么使用 MySQL 的 FROM_UNIXTIME() 函数把 INT 列转为 Date 类型。下面的查询展示了 FROM_UNIXTIME() 函数的用法:
|
SELECT
id, measured_on, FROM_UNIXTIME(measured_on)
FROM
vertabelo.inttimestampmeasures
WHERE
FROM_UNIXTIME(measured_on) > '2016-01-01'
LIMIT 5;
|
这会正确地获取到日期在 2016-01-01 之后的记录。你也可以直接比较数字和 2016-01-01 的 Unix 时间戳表示形式,即 1451606400。这样做意味着不用使用任何特殊的函数,因为你是在直接比较数字。查询如下:
|
SELECT
id, measured_on, FROM_UNIXTIME(measured_on)
FROM
vertabelo.inttimestampmeasures
WHERE
measured_on > 1451606400
LIMIT 5;
|
假如这种方式不够高效甚至提前做这种转换是不可行的话,那该怎么办?例如,你想获取 2016 年所有星期三的记录。要做到这样而不使用任何 MySQL 日期函数,你就不得不查出 2016 年每个星期三的开始和结束时间的 Unix 时间戳。然后你不得不写很大的查询,至少要在 WHERE 中包含 104 个比较。(2016 年有 52 个星期三,你不得不考虑一天的开始(0:00 am)和结束(11:59:59 pm)…) 结果是你很可能最终会使用 FROM_UNIXTIME() 转换函数。既然如此,为什么不试下真正的日期类型呢? 使用 Datetime 和 TimestampDatetime 和 Timestamp 几乎以同样的方式工作。两种都保存日期和时间信息,毫秒部分最高精确度都是 6 位数。同时,使用人类可读的日期形式如 “2016-01-01″ (为了便于比较)都能工作。查询时两种类型都支持“宽松格式”。宽松的语法允许任何标点符号作为分隔符。例如,”YYYY-MM-DD HH:MM:SS” 和 “YY-MM-DD HH:MM:SS” 两种形式都可以。在宽松格式情况下以下任何一种形式都能工作:
|
2012-12-31 11:30:45
2012^12^31 11+30+45
2012/12/31 11*30*45
2012@12@31 11^30^45
|
其它宽松格式也是允许的;你可以在 MySQL 参考手册 找到所有的格式。 默认情况下,Datetime 和 Timestamp 两种类型查询结果都以标准输出格式显示 —— 年-月-日 时:分:秒 (如 2016-01-01 23:59:59)。如果使用了毫秒部分,它们应该以小数值出现在秒后面 (如 2016-01-01 23:59:59.5)。 Timestamp 和 Datetime 的核心不同点主要在于 MySQL 在内部如何表示这些信息:两种都以二进制而非字符串形式存储,但在表示日期/时间部分时 Timestamp (4 字节) 比 Datetime (5 字节) 少使用 1 字节。当保存毫秒部分时两种都使用额外的空间 (1-3 字节)。如果你存储 150 万条记录,这种 1 字节的差异是微不足道的: 150 万条记录 * 每条记录 1 字节 / (1048576 字节/MB) = 1.43 MB
Timestamp 节省的 1 字节是有代价的:你只能存储从 ‘1970-01-01 00:00:01.000000’ 到 ‘2038-01-19 03:14:07.999999’ 之间的时间。而 Datetime 允许你存储从 ‘1000-01-01 00:00:00.000000’ 到 ‘9999-12-31 23:59:59.999999’ 之间的任何时间。 另一个重要的差别 —— 很多 MySQL 开发者没意识到的 —— 是 MySQL 使用服务器的时区转换 Timestamp 值到它的 UTC 等价值再保存。当获取值是它会再次进行时区转换,所以你得回了你“原始的”日期/时间值。有可能,下面这些情况会发生。 理想情况下,如果你一直使用同一个时区,MySQL 会获取到和你存储的同样的值。以我的经验,如果你的数据库涉及时区变换,你可能会遇到问题。例如,服务器变化(比如,你把数据库从都柏林的一台服务器迁移到加利福尼亚的一台服务器上,或者你只是修改了一下服务器的时区)时可能会发生这种情况。不管哪种方式,如果你获取数据时的时区是不同的,数据就会受影响。 Datetime 列不会被数据库改变。无论时区怎样配置,每次都会保存和获取到同样的值。就我而言,我认为这是一个更可靠的选择。 MySQL 文档: MySQL 把 TIMESTAMP 值从当前的时区转换到 UTC 再存储,获取时再从 UTC 转回当前的时区。(其它类型如 DATETIME 不会这样,它们会“原样”保存。) 默认情况下,每个连接的当前时区都是服务器的时区。时区可以基于连接设置。只要时区设置保持一致,你就能得到和保存的相同的值。如果你保存了一个 TIMESTAMP 值,然后改变了时区再获取这个值,获取到的值和你存储的是不同的。这是因为在写入和查询的会话上没有使用同一个时区。当前时区可以通过系统变量 time_zone 的值得到。更多信息,请查看 MySQL Server Time Zone Support。
对比总结在深入探讨使用各数据类型的性能差异之前,让我们先看一个总结表格以给你更多了解。每种类型的弱点以红色显示。 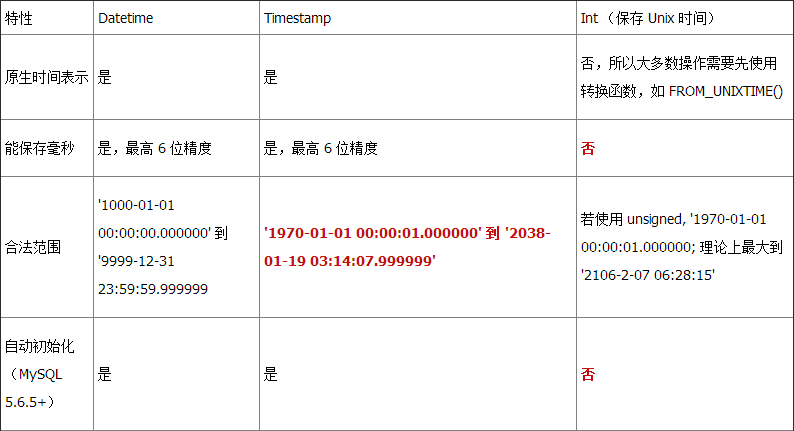


基准测试 INT、Timestamp 和 Datetime 的性能为了比较这些类型的性能,我会使用我创建的一个天气预报网络的 150 万记录(准确说是 1,497,421)。这个网络每分钟都收集数据。为了让这些测试可复现,我已经删除了一些私有列,所以你可以使用这些数据运行你自己的测试。 基于我原始的表格,我创建了三个版本: datetimemeasures 表在 measured_on 列使用 Datetime 类型,表示天气预报记录的测量时间
timestampmeasures 表在 measured_on 列使用 Timestamp 类型
inttimestampmeasures 表在 measured_on 列使用 INT (unsigned) 类型
这三个表拥有完全相同的数据;唯一的差别就是 measured_on 字段的类型。所有表都在 measured_on 列上设置了一个索引。 基准测试工具为了评估这些数据类型的性能,我使用了两种方法。一种基于 Sysbench,它的官网是这么描述的: “… 一个模块化、跨平台和多线程的基准测试工具,用以评估那些对运行高负载数据库的系统非常重要的系统参数。” 这个工具是 MySQL 文档中推荐的。 如果你使用 Windows (就像我),你可以下载一个包含可执行文件和我使用的测试查询的 zip 文件。它们基于 一种推荐的基准测试方法。 为了执行一个给定的测试,你可以使用下面的命令(插入你自己的连接参数):
|
sysbench --MySQL-table-engine=innodb --MySQL-db=vertabelo --MySQL-user=root --MySQL-host=localhost --MySQL-password= --test=sysbench_test_file.lua --num-threads=8 --max-requests=100 run
|
这会正常工作,这里 sysbench_test_file.lua 是测试文件,并包含了各个测试中指向各个表的 SQL 查询。 为了进一步验证结果,我也运行了 mysqlslap。它的官网是这么描述的: “mysqlslap 是一个诊断程序,为模拟 MySQL 服务器的客户端负载并报告各个阶段的用时而设计。它工作起来就像是很多客户端在同时访问服务器。” 记得这些测试中最重要的不是所需的绝对时间。而是在不同数据类型上执行相同查询时的相对时间。这两个基准测试工具的测试时间不一定相同,因为不同工具的工作方式不同。重要的是数据类型的比较,随着我们深入到测试中,这将会变得清楚。 基准测试我将使用三种可以评估几个性能方面的查询: 在 Datetime 和 Timestamp 数据类型上这允许我们直接比较而不需要使用任何特殊的日期函数。 同时,我们可以评估在 INT 类型的列上使用日期函数相对于使用简单的数值比较的影响。为了做到这些我们需要把范围转换为 Unix 时间戳数值。 与前个测试中比较操作针对一个简单的 DATE 值相反,这个测试使得我们可以评估使用日期函数作为 “WHERE” 子句的一部分的性能。 我们还可以测试一个场景,即我们必须使用一个函数将 INT 列转换为一个合法的 DATE 类型然后执行查询。 作为对前面测试的补充,这将评估在三种不同的表示类型上进行典型的统计查询的性能。 我们将在这些测试中覆盖一些常见的场景,并看到三种类型上的性能表现。 关于 SQL_NO_CACHE当在查询中使用 SQL_NO_CACHE 时,服务器不使用查询缓存。它既不检查查询缓存以确认结果是不是已经在那儿了,也不会保存查询结果。因此,每个查询将反映真实的性能影响,就像每次查询都是第一次被调用。 测试 1:选择一个日期范围中的值这个查询返回总计 1,497,421 行记录中的 75,706 行。 查询 1 和 Datetime:
|
SELECT SQL_NO_CACHE
measured_on
FROM
vertabelo.datetimemeasures m
WHERE
m.measured_on > '2016-01-01 00:00:00.0'
AND m.measured_on < '2016-02-01 00:00:00.0';
|
性能 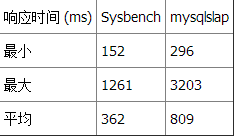
|
Sysbench cmd> sysbench --MySQL-table-engine=innodb --MySQL-db=vertabelo --MySQL-user=root --MySQL-host=localhost --MySQL-password= --test=datetime.lua --num-threads=8 --max-requests=100 run
|
|
mysqlslap cmd> mysqlslap --query="SELECT SQL_NO_CACHE measured_on FROM vertabelo.datetimemeasures m WHERE m.measured_on > '2016-01-01 00:00:00.0' AND m.measured_on < '2016-02-01 00:00:00.0'" --host=localhost --user=root --concurrency=8 --iterations=100 --no-drop --create-schema=vertabelo
|
查询 1 和 Timestamp:
|
SELECT SQL_NO_CACHE
measured_on
FROM
vertabelo.timestampmeasures m
WHERE
m.measured_on > '2016-01-01 00:00:00.0'
AND m.measured_on < '2016-02-01 00:00:00.0';
|
性能 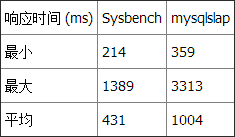
|
Sysbench cmd> sysbench --MySQL-table-engine=innodb --MySQL-db=vertabelo --MySQL-user=root --MySQL-host=localhost --MySQL-password= --test=timestamp.lua --num-threads=8 --max-requests=100 run
|
|
mysqlslap cmd> mysqlslap --query="SELECT SQL_NO_CACHE measured_on FROM vertabelo.timestampmeasures m WHERE m.measured_on > '2016-01-01 00:00:00.0' AND m.measured_on < '2016-02-01 00:00:00.0'" --host=localhost --user=root --concurrency=8 --iterations=100 --no-drop --create-schema=vertabelo
|
查询 1 和 INT:
|
SELECT SQL_NO_CACHE
measured_on
FROM
vertabelo.inttimestampmeasures m
WHERE
FROM_UNIXTIME(m.measured_on) > '2016-01-01 00:00:00.0'
AND FROM_UNIXTIME(m.measured_on) < '2016-02-01 00:00:00.0';
|
性能 
|
Sysbench cmd> sysbench --MySQL-table-engine=innodb --MySQL-db=vertabelo --MySQL-user=root --MySQL-host=localhost --MySQL-password= --test=int.lua --num-threads=8 --max-requests=100 run
|
|
mysqlslap cmd> mysqlslap --query="SELECT SQL_NO_CACHE measured_on FROM vertabelo.inttimestampmeasures m WHERE FROM_UNIXTIME(m.measured_on) > '2016-01-01 00:00:00.0' AND FROM_UNIXTIME(m.measured_on) < '2016-02-01 00:00:00.0'" --host=localhost --user=root --concurrency=8 --iterations=100 --no-drop --create-schema=vertabelo
|
另一种 INT 上的查询 1: 由于这是个相当直接的范围搜索,而且查询中的日期可以轻易地转为简单的数值比较,我将它包含在了这个测试中。结果证明这是最快的方法 (你大概已经预料到了),因为它仅仅是比较数字而没有使用任何日期转换函数:
|
SELECT SQL_NO_CACHE
measured_on
FROM
vertabelo.inttimestampmeasures m
WHERE
m.measured_on > 1451617200
AND m.measured_on < 1454295600;
|
性能 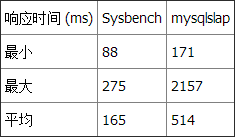
|
Sysbench cmd> sysbench --MySQL-table-engine=innodb --MySQL-db=vertabelo --MySQL-user=root --MySQL-host=localhost --MySQL-password= --test=basic_int.lua --num-threads=8 --max-requests=100 run
|
|
mysqlslap cmd> mysqlslap --query="SELECT SQL_NO_CACHE measured_on FROM vertabelo.inttimestampmeasures m WHERE m.measured_on > 1451617200 AND m.measured_on < 1454295600" --host=localhost --user=root --concurrency=8 --iterations=100 --no-drop --create-schema=vertabelo
|
测试 1 总结 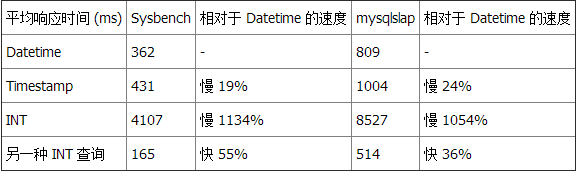
两种基准测试工具都显示 Datetime 比 Timestamp 和 INT 更快。但 Datetime 没有我们在另一种 INT 查询中使用的简单数值比较快。 测试 2:选择星期一产生的记录这个查询返回总计 1,497,421 行记录中的 221,850 行。 查询 2 和 Datetime:
|
SELECT SQL_NO_CACHE measured_on
FROM
vertabelo.datetimemeasures m
WHERE
WEEKDAY(m.measured_on) = 0; # MONDAY
|
性能 
|
Sysbench cmd> sysbench --MySQL-table-engine=innodb --MySQL-db=vertabelo --MySQL-user=root --MySQL-host=localhost --MySQL-password= --test=datetime_1.lua --num-threads=8 --max-requests=100 run
|
|
mysqlslap cmd> mysqlslap --query="SELECT SQL_NO_CACHE measured_on FROM vertabelo.datetimemeasures m WHERE WEEKDAY(m.measured_on) = 0" --host=localhost --user=root --concurrency=8 --iterations=25 --no-drop --create-schema=vertabelo
|
查询 2 和 Timestamp:
|
SELECT SQL_NO_CACHE
measured_on
FROM
vertabelo.timestampmeasures m
WHERE
WEEKDAY(m.measured_on) = 0; # MONDAY
|
性能 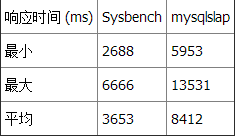
|
Sysbench cmd> sysbench --MySQL-table-engine=innodb --MySQL-db=vertabelo --MySQL-user=root --MySQL-host=localhost --MySQL-password= --test=timestamp_1.lua --num-threads=8 --max-requests=100 run
|
|
mysqlslap cmd> mysqlslap --query="SELECT SQL_NO_CACHE measured_on FROM vertabelo.timestampmeasures m WHERE WEEKDAY(m.measured_on) = 0" --host=localhost --user=root --concurrency=8 --iterations=25 --no-drop --create-schema=vertabelo
|
查询 2 和 INT:
|
SELECT SQL_NO_CACHE
measured_on
FROM
vertabelo.inttimestampmeasures m
WHERE
WEEKDAY(FROM_UNIXTIME(m.measured_on)) = 0; # MONDAY
|
性能 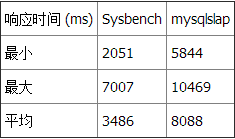
|
Sysbench cmd> sysbench --MySQL-table-engine=innodb --MySQL-db=vertabelo --MySQL-user=root --MySQL-host=localhost --MySQL-password= --test=int_1.lua --num-threads=8 --max-requests=100 run
|
|
mysqlslap cmd> mysqlslap --query="SELECT SQL_NO_CACHE measured_on FROM vertabelo.inttimestampmeasures m WHERE WEEKDAY(FROM_UNIXTIME(m.measured_on)) = 0" --host=localhost --user=root --concurrency=8 --iterations=25 --no-drop --create-schema=vertabelo
|
测试 2 总结 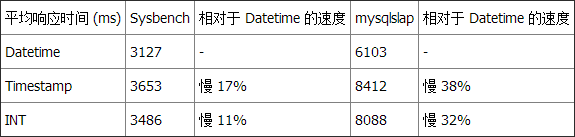
再次,在两个基准测试工具中 Datetime 比 Timestamp 和 INT 快。但在这个测试中,INT 查询 —— 即使它使用了一个函数以转换日期 —— 比 Timestamp 查询更快得到结果。 测试 3:选择星期一产生的记录总数这个查询返回一行,包含产生于星期一的所有记录的总数(从总共 1,497,421 行可用记录中)。 查询 3 和 Datetime:
|
SELECT SQL_NO_CACHE
COUNT(measured_on)
FROM
vertabelo.datetimemeasures m
WHERE
WEEKDAY(m.measured_on) = 0; # MONDAY
|
性能 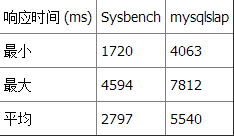
|
Sysbench cmd> sysbench --MySQL-table-engine=innodb --MySQL-db=vertabelo --MySQL-user=root --MySQL-host=localhost --MySQL-password= --test=datetime_1_count.lua --num-threads=8 --max-requests=100 run
|
|
mysqlslap cmd> mysqlslap --query="SELECT SQL_NO_CACHE COUNT(measured_on) FROM vertabelo.datetimemeasures m WHERE WEEKDAY(m.measured_on) = 0" --host=localhost --user=root --concurrency=8 --iterations=25 --no-drop --create-schema=vertabelo
|
查询 3 和 Timestamp:
|
SELECT SQL_NO_CACHE
COUNT(measured_on)
FROM
vertabelo.timestampmeasures m
WHERE
WEEKDAY(m.measured_on) = 0; # MONDAY
|
性能 
|
Sysbench cmd> sysbench --MySQL-table-engine=innodb --MySQL-db=vertabelo --MySQL-user=root --MySQL-host=localhost --MySQL-password= --test=timestamp_1_count.lua --num-threads=8 --max-requests=100 run
|
|
mysqlslap cmd> mysqlslap --query="SELECT SQL_NO_CACHE COUNT(measured_on) FROM vertabelo.timestampmeasures m WHERE WEEKDAY(m.measured_on) = 0" --host=localhost --user=root --concurrency=8 --iterations=25 --no-drop --create-schema=vertabelo
|
查询 3 和 INT:
|
SELECT SQL_NO_CACHE
COUNT(measured_on)
FROM
vertabelo.inttimestampmeasures m
WHERE
WEEKDAY(FROM_UNIXTIME(m.measured_on)) = 0; # MONDAY
|
性能 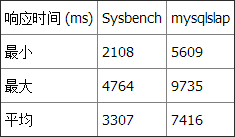
|
Sysbench cmd> sysbench --MySQL-table-engine=innodb --MySQL-db=vertabelo --MySQL-user=root --MySQL-host=localhost --MySQL-password= --test=int_1_count.lua --num-threads=8 --max-requests=100 run
|
|
mysqlslap cmd> mysqlslap --query="SELECT SQL_NO_CACHE COUNT(measured_on) FROM vertabelo.inttimestampmeasures m WHERE WEEKDAY(FROM_UNIXTIME(m.measured_on)) = 0" --host=localhost --user=root --concurrency=8 --iterations=25 --no-drop --create-schema=vertabelo
|
测试 3 总结 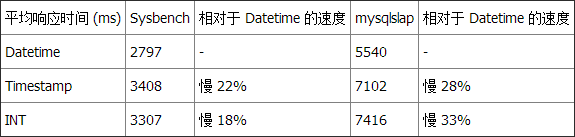
再一次,两个基准测试工具都显示 Datetime 比 Timestamp 和 INT 快。不能判断 INT 是否比 Timestamp 快,因为 mysqlslap 显示 INT 比 Timestamp 略快而 Sysbench 却相反。 注意: 所有测试都是在一台 Windows 10 机器上本地运行的,这台机器拥有一个双核 i7 CPU,16GB 内存,运行 MariaDB v10.1.9,使用 innoDB 引擎。 结论基于这些数据,我确信 Datetime 是大多数场景下的最佳选择。原因是: - 更快(根据我们的三个基准测试)。
- 无需任何转换即是人类可读的。
- 不会因为时区变换产生问题。
- 只比它的对手们多用 1 字节
- 支持更大的日期范围(从 1000 年到 9999 年)
如果你只是存储 Unix 时间戳(并且在它的合法日期范围内),而且你真的不打算在它上面使用任何基于日期的查询,我觉得使用 INT 是可以的。我们已经看到,它执行简单数值比较查询时非常快,因为只是在处理简单的数字。 Timestamp 怎么样呢?如果 Datetime 相对于 Timestamp 的优势不适用于你特殊的场景,你最好使用时间戳。阅读这篇文章后,你对三种类型间的区别应该有了更好的理解,可以根据你的需要做出最佳的选择。 | 





